 Bots are currently scraping the internet for LLM training data at unprecedented rates[1][2][3], driving up costs and destabilizing public-facing websites. I want to talk about how this has been particularly difficult for wikis, and has gotten much worse in the last few months.
Bots are currently scraping the internet for LLM training data at unprecedented rates[1][2][3], driving up costs and destabilizing public-facing websites. I want to talk about how this has been particularly difficult for wikis, and has gotten much worse in the last few months.
I run Weird Gloop, which hosts some of the biggest video game wikis ever, like Minecraft, OSRS and League. Over the last 3 years, we’ve had to spend more and more of our time fighting with this bot traffic that is spiky, disproportionately expensive, and getting harder to distinguish from humans. If we weren’t constantly mitigating the bots, they would use ~10x more of our compute resources than everything else put together - even though that “everything else” includes tens of millions of (human) pageviews and tens of thousands of edits a day.
Everyone who runs wikis is dealing with the exact same problem. The Wikimedia Foundation has a post about it impacting operations, every major wiki farm has had varying degrees of service outages, and some smaller independent wikis have been knocked completely offline. Overall, I’d guess that about 95% of all server issues in the wiki ecosystem this year have been caused by bad scrapers.
Every wiki sysadmin I’ve talked to is dealing with these specific problems:
The scrapers are pretending to be human visitors, and getting pretty good at it
Most of the discussion I’ve seen about scrapers has focused on bots operated by the major AI companies (GPTBot, ClaudeBot, PerplexityBot, etc). Although these “official” bots have at times struggled to respect robots.txt, at least they usually properly identify themselves as bots in their User Agent string, which makes it really easy for a website operator to block them with Cloudflare, nginx, or any number of other techniques.
The problem is that when webmasters started blocking AI scrapers based on User Agent, it created a massive incentive for bots to pretend to be human traffic, so as to avoid getting blocked. This game of cat and mouse has played out over the last few years, and the bots have gotten pretty darn good at imitating human requests. Now the majority of AI scraper traffic that hits our wikis is carefully crafting the requests, sending the right headers so it can pretend to be recent versions of Google Chrome, which eliminates the obvious “bot or real person” signals that we previously could use to block them.
They’re using tens of millions of IP addresses
Before 2023, if we had a problem with how someone was scraping the wiki, 95% of the time they would only be using a single IP address, or a single datacenter with a small subnet of IPs. So it was mostly effective to block bad actors based on IP or ISP characteristics.
…Enter residential proxies, where anyone with a credit card can get all of their scraping requests “laundered” through a network of millions of IP addresses. The wikis get hit sometimes by scraper runs that cycle through a million IPs a day, and they >look like< they’re coming from legit places: mostly residential ISPs (Comcast, AT&T, Charter, etc) where the customer probably doesn’t even know their IP is being used as an exit node for a residential proxy.
Beyond residential proxies, a lot of the scraping is happening on IPs that belong to Facebook and Google. Bad actors are able to use facebookexternalhit link preview or Google Translate to make the requests happen on Google/Facebook servers, which completely obscures the source of the requests. At times we’ve had to break Google Translate’s URL tool for all our wikis, because 99.99% of the requests coming through it are abusive.
They’re mostly crawling stupid URLs
Most of these AI scrapers seem to select their targets in the dumbest way possible:
- visit the homepage of the wiki
- visit all the links on that page
- visit all the links on THOSE pages
- …
- repeat until all links are visited
They don’t seem to have any awareness that there’s a robots.txt and sitemap that tells them which URLs are worth scraping. There’s a reason this is an especially dumb strategy for wikis.
OSRS Wiki has about 40,000 “articles”, so that’s 40,000 URLs that make up the vast majority of the useful information on the site. But once you account for all the old revisions, edit screens and special pages that are used by people editing the wiki, there’s at least a billion navigable URLs. That means two things for scrapers hitting wikis:
- this naive scraping process is never going to finish
- the vast majority of the requests are not doing anything useful

Most of these URLs can’t possibly be useful data for training an LLM, but it seems like that’s what they’re spending most of their resources on. These weird requests are also unusually expensive for us to serve, since they bypass the various layers of caching that most requests from real users hit. Cache hits usually take less than 20 milliseconds of processing time, but these weird old diffs can frequently take 1-2 seconds. This means that top-line metrics (“8 million bot requests a day”, “bots are using 65% of my bandwidth”, etc) seriously undersell the scope of the problem, because CPU capacity is usually the important bottleneck, and the bot requests with all the weird query parameters are often 50-100x as expensive to serve.
The worst bot traffic is very spiky, so aggregate metrics undersell the problem
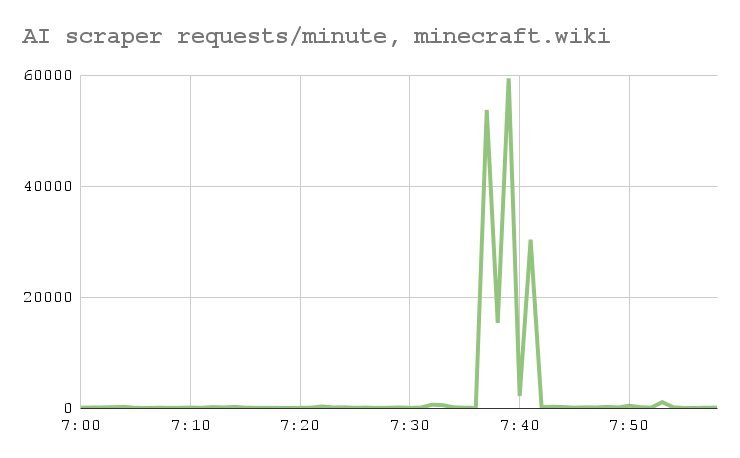
I said earlier that we get about 250 million bot requests per month (about 100 per second), but that’s just the long term average: these scrapers frequently operate in short bursts of 1000+ requests a second, almost indistinguishable from a good old-fashioned DDOS attack. So even though the bots might only be ~50% of our total CPU usage long-term, their abusive traffic spikes are responsible for ~95% of the slowness and outages that wikis have been dealing with.
It’s not clear who’s doing it
I keep calling this bad traffic “AI scrapers”, but because everyone’s pretending to be Google Chrome, I have no idea who’s actually responsible for it, or what they’re doing with all the wiki data they’re slurping up. Is it a data broker? A frontier lab double-dipping? Is it just random independent projects with access to residential proxies? Am I underestimating how low the barrier to entry is now?
I really have no idea. If by some miracle, someone reading this is behind one of these efforts…honestly, send me an email or something. I would love to know what you’re getting out of this, and find a less stupid way for you to do it.
What’s worked for us
The whole situation sounds kinda grim, right? If this were a sales pitch, this is about the point where I’d switch gears and tell you we have some magic solution to sell you for a million bucks. We don’t, I’m pretty sure it’s just a really hard problem that everyone’s struggling with.
The most common technique is to put your website behind something like Cloudflare challenges or Anubis, which has become ubiquitous on the internet in the last year. This kind of works, but has two main problems:

- There will be periods where some bots are able to consistently pass the challenges. We don’t have much insight into what methods they’re using, but I would assume there’s an arms race going on behind-the-scenes between Cloudflare and the bot developers. Cloudflare is winning that battle maybe 90% of the time, but that remaining 10% can be rough.
- Actual readers hate having to see the challenges before they get to the wiki. Can you blame them? So ideally you have good heuristic rules that decide what traffic is worth challenging, so most people aren’t impacted…which just gets back to it being hard to reliably detect which traffic is automated.
Pretty much everyone has some handwritten firewall rules that will be specific to their infra and the attacks they’ve had in the past. Most often these filters will be based on specific User Agent strings, IP groups or ASNs. We do most of this at the Cloudflare/CDN level, but some other wikis do it on the nginx/webserver side instead.
Blocking just on User Agent/IP is, of course, rarely sufficient these days. So over time we’ve had to look at more complicated attributes of the requests - HTTP version, headers, TLS ciphers and ja4-related hashes - to try to find simple rules for which traffic is bots.
One perspective we’ve found really useful is to look for things humans do in aggregate, that the bots don’t do. For wikis that run the MediaWiki software (like us), there are many types of HTTP requests that normal people on real browsers often make when they use the wiki, that the bots usually don’t. So if you see some chunk of traffic that you can segment off (based on headers, ja4 hashes, whatever else…), that visits a lot of articles but doesn’t do any of the classic “human” requests, it’s a strong indicator that you could get away with challenging that chunk.
This technique, of looking at the human-behavior requests that aren’t present in the bot traffic, is quite powerful. We started building a system that looks at our “missing” traffic and automatically proposes “decision tree”-based heuristics for which traffic to challenge. In testing so far, it seems to do an excellent job of rooting out nearly all of the scrapers, but I’ve hesitated to let it run unsupervised because we don’t have a clear idea of what sort of false positives it would create for people with unusual browsing habits (NoScript users, screen readers, unexpected types of devices). I also don’t love the idea of building and permanently maintaining our own ML/data analysis infrastructure for this. I’d sure love to focus on making wikis instead.
There’s more exotic techniques out there, too:
- I’ve seen people have success identifying residential proxies based on TCP/TLS timing discrepancies
- There are companies out there selling realtime databases of residential proxy IPs, although it’s not clear to me how actionable that is when most residential proxies are also used by real people at the same time.
- This bot-detection problem feels intuitively like it should be solvable at scale, where someone like Cloudflare or the big cloud providers could use the packet-level network info from their absurd amount of traffic to make awesome heuristics…but nobody I’ve talked to has been impressed with the heuristics on any of these commercial bot detection products, including the ones that run to six-figures a year.
Some other ideas that are bad for readers
There’s a couple “nuclear options” for stopping AI scrapers, but they are much more disruptive for real people. The most common I’ve seen:
- Require readers to log in to view any pages that could potentially be expensive to generate. This is what Fandom did on all their wikis a few months ago
- Serve Cloudflare challenges to all traffic
Both of these are understandable things to do as a webmaster, but they’re terrible for the long-term health of the wikis and their communities. The main lesson I’ve learned from 16 years of building wiki communities is that the best thing you can do to attract new contributors to a wiki is to eliminate friction - make things easier to edit, easier to explore the internals of the wiki, and tear down the barriers-to-entry that separate the readers from the editors.
All of these more extreme anti-bot techniques add new friction, and have predictable consequences - I did a small analysis and found that contributions from new users across Fandom are down about 40% after Fandom’s changes that hid “internal pages” from the >95% of readers that don’t have accounts. It would be hard for me to ever think that’s a worthwhile tradeoff.
Where do we go from here?
Just so people don’t get too bummed out - we’re still doing okay! As much as I wish I could turn the clock back 3 years and never have to deal with this scraper nonsense again…I still love hosting wikis, I love helping wikis move off Fandom, and I can’t imagine a scenario where the bots seriously change either part of that. I have longer-term concerns about “AI Overviews” killing the pipeline that turns wiki readers into wiki contributors, but that’s a story for another day.
I’ve had a couple friends even half-seriously suggest that the wave of bots might even be good for Weird Gloop, because we’re better-than-average at MediaWiki tech stuff, and maybe we benefit because scrapers raised the bar for expertise and time needed to host a wiki. But I think the internet is worse off if people can’t easily host wikis. I can imagine a nightmare scenario where you eventually need an oncall rotation or an ML engineer or an enterprise product if you want to host a wiki without getting intermittently splattered by scraper bots…this would be extremely bad news for the independent wiki community overall.
I’m not really sure what the endgame is here. I suspect the arms race between bot owners and webmasters will continue until someone comes up with a clever way to change the structural incentives around scraping. For example, I think Cloudflare’s new crawling API could possibly change the dynamic, if using that API ends up being less effort for the bots than building their own systems that ignore robots.txt and cause problems for us. Of course I’d prefer the scraping just didn’t happen at all, but we probably can’t un-ring that bell.
But! The thing that makes me optimistic is that there are literally thousands of people out there just like us - running their websites and finding more and more clever techniques to deal with the bots. I’ve heard some very cool, very specific ideas from other sysadmin folks in private conversations, and I have to assume there’s a lot of discussion happening in random Slacks and Discords and other small groups. But I wish there was more public discussion about the practicalities and specifics, because a lot of sysadmins I talk to don’t realize the extent to which their problems are identical to everyone else’s.
I understand not everyone wants to tell the whole world how they’re stopping the bots, because they’re worried they’ll lose whatever edge they have. I have a slight fear that my post here will make our own tactics less effective, but if it helps people put their heads together, it’s worth it.
So with that in mind:
- If you’re a sysadmin dealing with AI scrapers in any capacity, consider sharing what’s worked for you, in whatever space makes sense for you
- If you’re a company that is selling a product that purports to solve this bot problem, PLEASE put out more case studies with tangible data about precision and recall rates in non-contrived situations. The people making purchasing decisions on this topic aren’t just checking off a box, they really care about the results.
- If you run a wiki (or other indie website) and you wanna talk shop about bot detection, send me an email or Discord message. I might make a little Discord server if there’s enough interest.