So…we made a guide! It’s a collection of practical things you’ll want to be thinking about if you’re moving your wiki off Fandom, based on the experiences that River, Momo, and I [cook] have had in the last few years, helping wikis big and small beat up Goliath and migrate somewhere better.
Some topics:
- Scripts for getting the relevant content onto your new wiki
- Some Fandom-specific stuff you’re going to want to convert or remove
- Advice for announcing the move on Reddit, with some examples
- Advice for working with the game developers and other important people in the community
I hope this gives everyone some tangible examples, demystifies the process, and makes it clear which parts of this are actually hard, vs which parts just look hard.
If you’re a wiki editor, go check it out! Even if you’re not a wiki editor, we have a section with some advice for how you can still help get the ball rolling for your favorite wiki.
Nearly everyone is gonna be rooting for the new wiki. Go build a coalition!
As we’ve helped more wikis get from the “idea stage” to actually launching and announcing the move away from Fandom, I’ve noticed a consistent gap in expectations, where the wiki admins think moving-from-Fandom is basically internal “hobby drama” that only affects editors, and nobody else will care. Naturally, this means they’re caught off guard when the move gets a huge amount of interest - 10k upvotes on Reddit with 99% support, YouTube videos with 4 million views, mainstream gaming press - by far the most attention the wiki’s ever gotten.
This is fascinating to me, and I think I finally get it: wiki editors consistently underestimate how much the average internet person uses their wiki every day, would benefit from the wiki being great, and consequently, is frustrated as heck with Fandom being so damn bad.
The most successful wiki moves are the ones where the wiki admins recognize this, and are pragmatic about building a coalition from their game’s wider community to help get the word out about the new wiki.
I cannot stress enough that this is usually the deciding factor for whether a wiki move is successful. Build the coalition! It’s not as hard as it sounds. Here’s two important groups you should be thinking about:
Game devs
I’ve yet to meet anyone working for a game studio that’s enthusiastic about their wiki being on Fandom. I don’t think this dynamic is widely understood by wiki editors.
For most editors, it’s insanely valuable to get a chance to talk to the devs: get some data, get some clarification on lore or mechanics…because it can make the wiki so much better, often with only a few minutes of effort from the developers. Fandom does an excellent job giving the impression to wiki editors that, because they’re a “big company” too, they’ll have an “in” with the game studio, and can make these kinds of interactions happen. In other words, it’s a “perk” of being on Fandom’s platform, that you can’t get anywhere else.
In my experience, the opposite is usually true! I’ve seen at least 3 times where a game studio will just refuse to engage with their game’s wiki because it was hosted on Fandom, tragically not understanding that the people making the edits were not the people running the horrible intrusive ads. It’s not that hard to see why:
- Game designers dislike it because they’ll often be reading it for work (a lot of the times the wiki is better than their internal documentation!), so they have all the same usability/ad complaints that your average reader would
- Community managers dislike it because the ad situation tanks community sentiment, and makes it harder for new players to find what they need
- Marketers freak out about how their core audience is getting bombarded with ads for games that directly compete with them (the developer of RuneScape had a fansite program circa 2013, that gave fansites special access to stuff if they agreed to not run ads for other video games, which, we learned years later, was mostly aimed at freezing out the Fandom wiki that was constantly running ads for WoW, etc)
The list goes on: here’s a video from the developer of Satisfactory talking about their unpleasant interactions with Fandom. A community manager for a different, very popular game once told me that their studio got fed up with the terrible ad situation on their Fandom wiki, and inquired with Fandom how much they’d have to pay to get the wiki to not have any ads. They stopped pursuing this when Fandom said they’d be willing to consider it…for about 5 million dollars a year. For just the one wiki.
So…go talk to your game’s community managers! There’s likely someone at the studio who understands how important the wiki is and is frustrated that it’s on Fandom, but who has no idea that the wiki contributors also want out. If that’s the case, there’s probably a reasonable path forward where you work together, and if you can find the right person to talk to at the studio, they’ll be your most important ally in the whole thing. There’s a lot they can do to put their thumb on the scale to help the new wiki, including:
- Helping announce the move, and linking to the wiki in prominent places on their website
- Putting the wiki on a subdomain of their website like wiki.leagueoflegends.com or wiki.warframe.com, or hosting it on their servers, like the Path of Exile devs
- Requesting a takedown of any content on the Fandom wiki that infringes their copyright, like art or other game assets
- Working more closely with the wiki editors on projects that make the wiki better (more on this at the end!)
YouTubers and other community “power users”
There’s a lot of great videos from established YouTubers that focus on a wiki leaving Fandom. This one about Hollow Knight is probably the most well-known, but there’s some popular ones from a few Minecraft people, League people, and more. These are one of the main ways that casual wiki readers find out about the move, so you should be doing everything you can to get popular video makers for your game to help spread the word.
Figure out who else is important - make friends with the Reddit and Discord mods, figure out what other websites and community projects rely on the wiki in some way, and see if they’re up to help.
Wiki editors will often assume they need to offer something in return (linking to the video, some official affiliation, etc), but you usually just don’t need this at all. In my experience like 95% of these folks are super eager to help, because remember, they all use the wiki too.
The light at the end of the tunnel
Every single person I know who’s moved their wiki off Fandom feels like it’s one of the best decisions they’ve ever made. It’s so, so, worth it. Here’s why:
You’ll probably beat Fandom on Google
Whenever I see a Reddit post complaining about Fandom, there’s a bunch of comments about how Fandom has some SEO voodoo that makes them always be the #1 result on Google. Fandom leans in to this narrative in their explanation for why you should keep your wiki there:
Forking is a drastic and often difficult move. We would, of course, like you to stay on Fandom! We have the advantage of a large and stable platform, with strong SEO and a large and dedicated staff team.
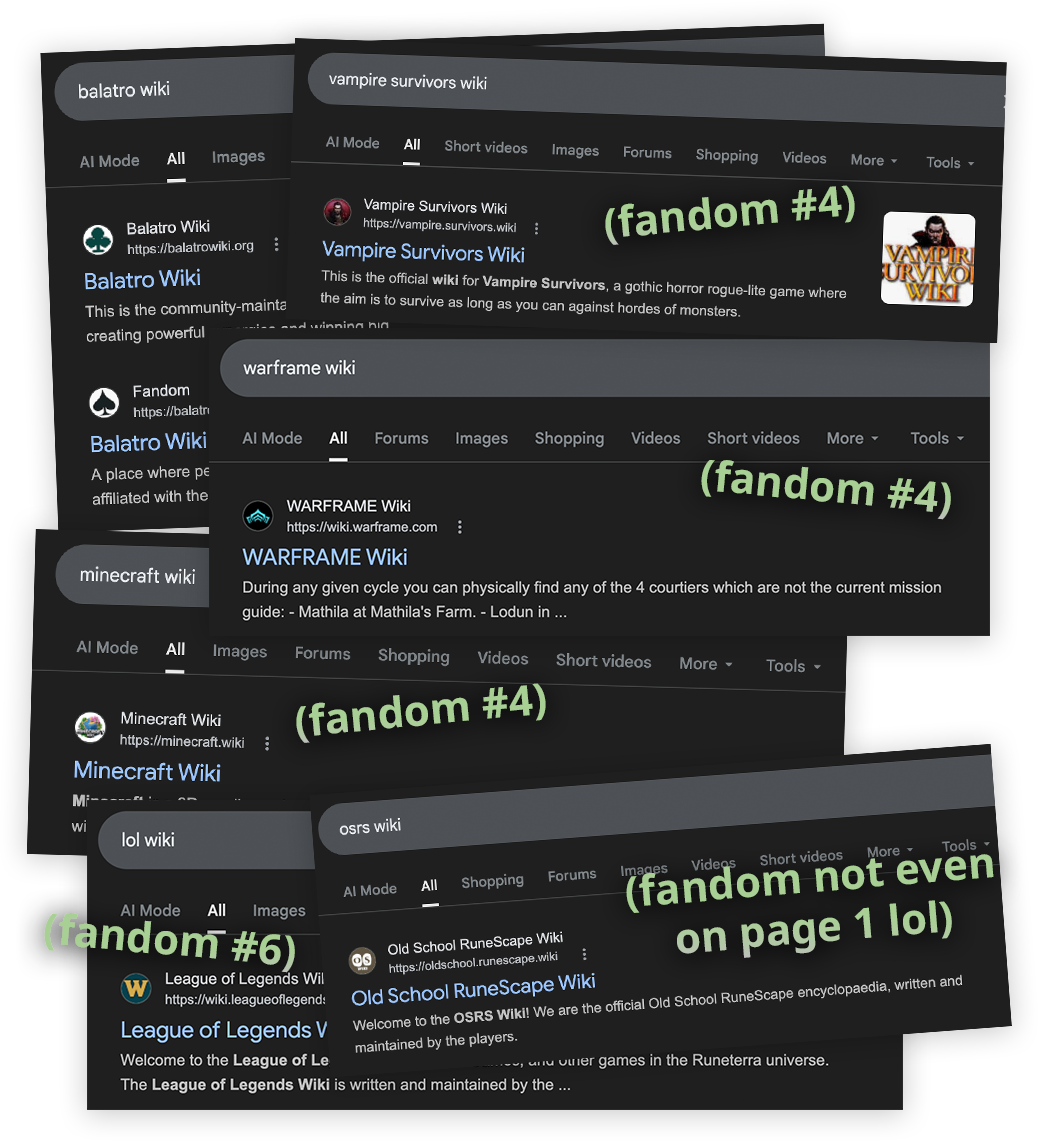
In my experience, this is pretty overblown. If you do a great job spreading the word, then droves of people will seek out the new wiki on Google, which bumps the click-through rate of the new wiki. In practice, Google is actually quite willing to “rank up” search results that out-perform expectations on click-through rate, and I believe the current consensus is that CTR is the most important Google ranking factor by a wide margin.
So Fandom doesn’t have a moat, you just need to do a great job yelling from the rooftops about the new wiki. Don’t believe me?
Your wiki (and community) are gonna get way better
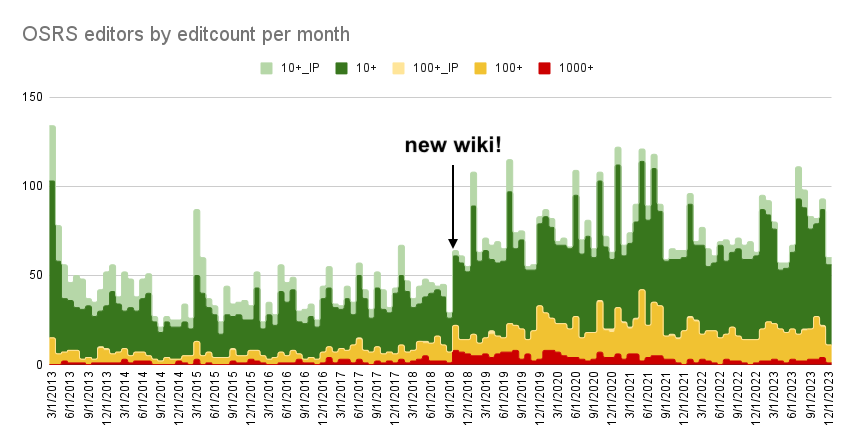
I noted in 2024 that every wiki we’d moved from Fandom ended up doubling the number people actively editing. In the 2 years since then, that pattern has not only held up, it’s gotten even bigger: on average, the rate of new editors on a wiki triples when they move away from Fandom. That’s three times as many people to help with game updates, work on new projects…everything, really. More contributors makes everything easier.
Moving away from Fandom also gives you a ton of new technical flexibility to implement cool shit - integrations that let you look things up from the game, sync your in-game progress to the the wiki…so many examples like this that the readers love, and that are just impossible to imagine happening on a Fandom wiki. Not to mention that once you get the game developer involved in the wiki and trusting the wiki editors, there are usually some very obvious areas for collaboration (like sharing game data, or pre-release access, or even just being open to answering questions) that will make the wiki massively better.
Go check out the guide! It’s got a ton of detailed, useful stuff I haven’t talked about here. If you’ve checked it out and want moving advice that’s specific to your situation, we just opened up the Weird Gloop discord, so come say hi there, or contact me another way.
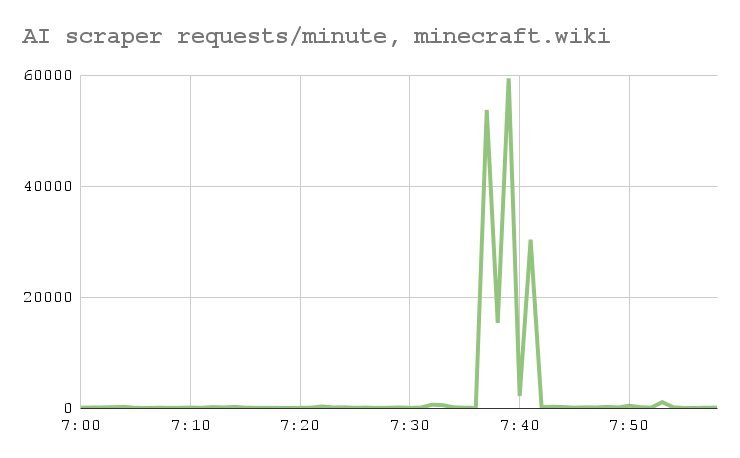
]]> Bots are currently scraping the internet for LLM training data at unprecedented rates[1][2][3], driving up costs and destabilizing public-facing websites. I want to talk about how this has been particularly difficult for wikis, and has gotten much worse in the last few months.
Bots are currently scraping the internet for LLM training data at unprecedented rates[1][2][3], driving up costs and destabilizing public-facing websites. I want to talk about how this has been particularly difficult for wikis, and has gotten much worse in the last few months.